これまではそれぞれ概要になっていたので、今回はもう少し深掘りする方向を意識しつつ記載したい。
前回リンク
概要
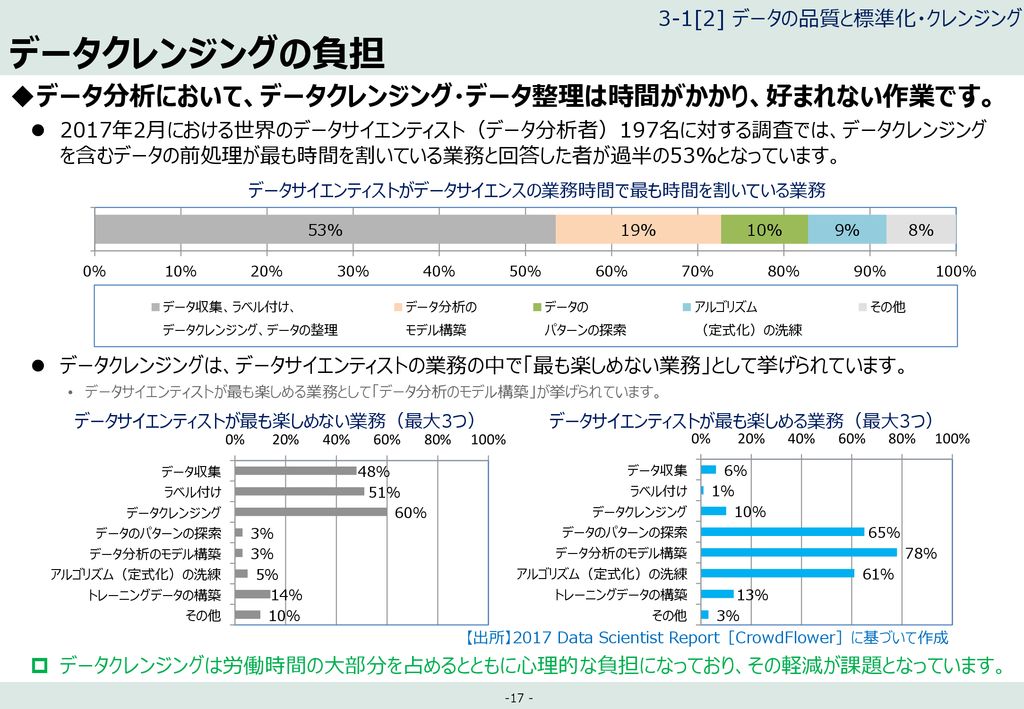
今回トピックにするのは、下記の気仙沼と世田谷の人口データを比較したもの。
いい具合にフォーマットがズレてくれていたので、ブルシット気味な無駄仕事、もといデータクレンジング、データエンジニアリングも意識しつつからの、データサイエンスに繋げられた一貫的なフローもそれはそれで尊いだろう。やや皮肉だが。
元データ
まずはすべての処理前の生の元データの一部を示す。
表形式になっているだけいいのだが、カラムの設定等に地域差がありすぎて使いにくいことこの上ない。
| 町丁 | 総数 | 0~4歳 | 5~9歳 | 10~14歳 | 15~19歳 | 20~24歳 | |||||||||
| 男 | 女 | 男 | 女 | 男 | 女 | 男 | 女 | 男 | 女 | 男 | 女 | ||||
| 総数 | 433,723 | 482,485 | 17,239 | 16,355 | 19,198 | 18,366 | 18,941 | 17,893 | 17,970 | 16,807 | 24,855 | 26,279 | |||
| 世田谷地域 | 119,314 | 133,240 | 4,676 | 4,554 | 4,965 | 4,884 | 4,499 | 4,370 | 4,217 | 4,069 | 6,756 | 7,300 | |||
| 池尻まちづくりセンター | 11,584 | 12,508 | 467 | 473 | 443 | 442 | 399 | 400 | 334 | 324 | 621 | 597 | |||
| 池尻1丁目 | 824 | 686 | 34 | 40 | 48 | 37 | 43 | 55 | 39 | 38 | 53 | 40 | |||
| 池尻2丁目 | 2,145 | 2,346 | 68 | 64 | 80 | 76 | 57 | 52 | 49 | 44 | 109 | 96 | |||
| 年齢 地区 | 0~4 | 5~9 | 10~14 | 15~19 | 20~24 | |
| 気仙沼 | 男 | 171 | 191 | 240 | 261 | 352 |
| 女 | 156 | 172 | 217 | 267 | 298 | |
| 計 | 327 | 363 | 457 | 528 | 650 | |
| 鹿折 | 男 | 69 | 82 | 84 | 111 | 94 |
| 女 | 74 | 72 | 90 | 97 | 104 | |
| 計 | 143 | 154 | 174 | 208 | 198 | |
その地域内だけであれば、それに併せて作業すればいいが、今回のような統合においては実質的に不可能とも言える。
今回はこの手間もあって2地域のみとした。これが人力で対応できる実質的限界点にも思えるからだ。もちろん無限のリソースがあれば不可能ではなかろうが。
Tableau(に限らず)、本当にサマライズ済みのデータはむしろ厄介で、各位にはプライバシーに配慮しつつ、なるべく生のマスターデータを提供いただきたいところが本音
— AOKI Takashige (@aochan_0119) 2022年7月12日
そもそも住民基本台帳ベースなのだろうから、それ自体を匿名化して公表するか、あるいはそこからのサマライズのルールを全国的に統一すべきだろう。現実性としては後者の方が高いか。また忙しいとされる役所業務の負担軽減にもなりそうだ。
ソースデータの整形
こうした形式をExcel等で確認した後、Tableauで使いやすいように読み込みの形式等をうまい具合に指定する。
もっとも最適化されたDB等であればこの作業は不要だ。
まずはデータインタープリターのチャックボックスを入れて不要な見出しを削除する。
ピボット
具体的にはデータがそれぞれ不要に横長になっているので、ピボットでこれを縦に変換する。
右端に総数・合計という変なデータがあるが、これは無視する。
気になるようであれば、データソース段階で削除してもいい。大規模なデータである場合も、作業の軽量化のために削除したほうがいいだろう。
属性分割
これで気仙沼のデータは属性の切り分けがうまくいった。しかし世田谷は属性に年齢と性別の両方が含まれてしまっており、扱いにくいことこの上ない。そこで数式を用いて、分割を図る。
今回の場合はキレイに空白があるので、ここの前後で切り分ける。
年齢
SPLIT(TRIM( SPLIT( [属性], " ", 1 ) ),"歳",1)
性別
SPLIT(TRIM( SPLIT( [属性], " ", 1 ) ),"歳",1)
補足:名称変更
ここまでの作業で、年齢、性別ごとの階級値に切り分けられた。市区ごとにカラム名が異なっており、ブレンディングや単純に見るときの項目名の違いが誤解の元となる懸念があるので、この段階でフィールド名も統一して変更しておこう。
複数市区を比較するにあたり、上記の分割のロジック組みとフィールド名変更が厄介なのは前述したとおりだ。
余談:前処理の負担
くどいようだがデータソースのキレイさによっては、以上の作業はしばしば不要だ。データクレンジング、データエンジニアリングの面倒さを痛感させられる。
https://slidesplayer.net/slide/14246648/
GUI操作でViz作成
シート
ここまで来れば後はTableauの特徴の簡単なGUI操作により一瞬だ。
今回は人口をトピックにしたので、せっかくなので人口ピラミッドを作ってみたい。本来であればBinを設定するところだが、サマライズされた統計データなので不要だ。
それぞれの領域にドラッグアンドドロップするだけなので、細かい補足は不要だろう。
年齢を縦軸とし、横軸をメジャーバリューの人口とする。ここで先述の通り総数はおかしなデータが入ったままなので無視する点に要注意だ。

元のデータの時点で合計にはなっているが、ひとまず合計を選んでおくこととしよう。平均でも表示内容は変わらないと思っていたら変わる。。!詳細は確認できていないが、条件に該当する変なセルがある分、平均として割る数にカウントされるものがありそうな気がする。簡単な分、ビジュアライズされるとミスに気づきにくいのは、便利さの代償として注意しなければならない。
そしてフィルターに性別を指定し、社会的にコンセンサスのとれている、男を青、女を赤に色付ける。また地域の項目もあるので、ここを市区全体になりつつ、総数のカラムが入らないように調整する。

男も基本的に同様だが、ピラミッドとして左右対称にしなければならない。今回は横着にメジャーにマイナスをつけた。
ダッシュボード
あとはこれをダッシュボードで同じようにくっつけてしまえば完成だ。最後の反転処理等が雑なものの、欲しい情報の粒度に応じてはこれくらいの手抜きは許されてほしいところだ。

ピラミッドのルールに従って左右に男女、ついでに上下に市区を比較した。本来的には集合横棒等の方が比較しやすいが、市区で一旦データがサマられてしまっている以上、それを解凍して再構成するのは骨が折れる。
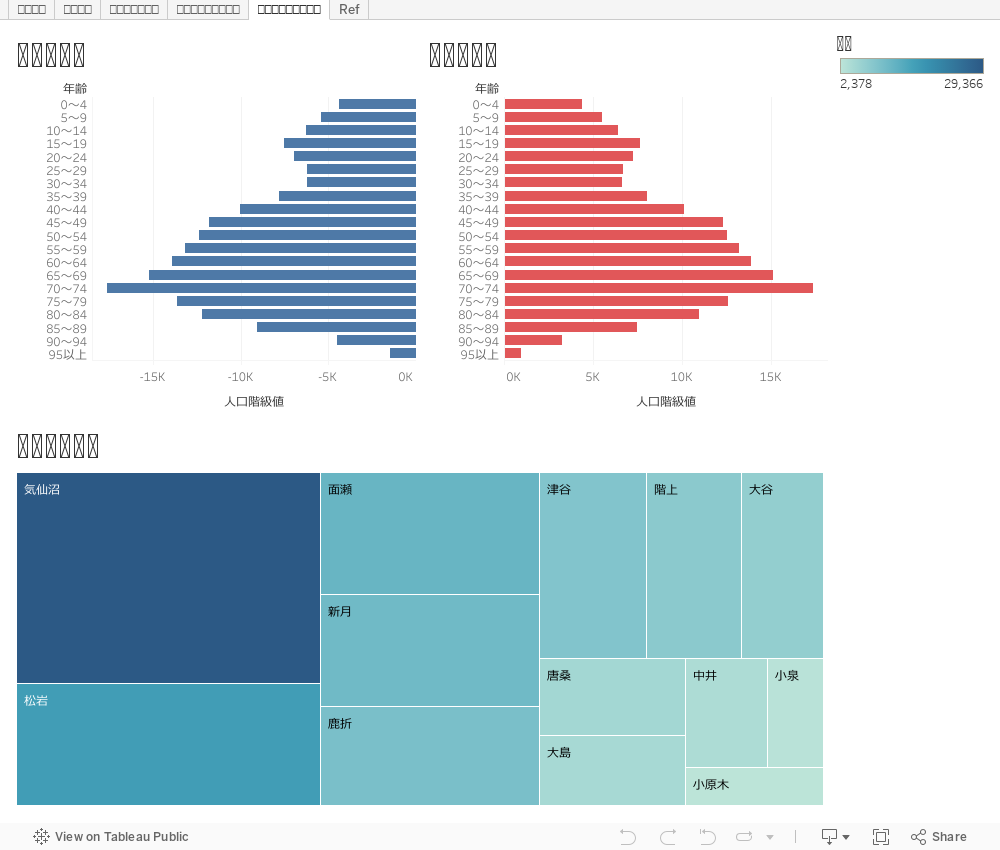
あるいは町目のデータもあるので、これとツリーマップを組み合わせて人口構成の比率を可視化しつつ、ブレイクダウンしやすくできるのもTableauの強みだ。
2市区比較
ここまででも大した成果になっていない割には手間がかかって疲れている。とはいえこれだけなら、最後のダッシュボードを除きExcelでも十分にできそうな内容を変に苦労したにすぎない印象も強いだろう。
そこで簡単であるが、地区をクロスさせて比較を試みた。
今回、気仙沼との交流の社内企画の絶好の機会に併せて、予てより気になっていた都市と地方の人口を比較してみた
— AOKI Takashige (@aochan_0119) 2022年7月12日
代表的に2都市とした
ひとまずデータ形式が整っておらず、ブレンディングやピボットの準備に苦慮した。。。https://t.co/kXn3l5vpO0 pic.twitter.com/SCDEAxaESq
人口ピラミッド違法建築

まずは人口ピラミッドの原理に反するところもあるが、左右:男女で市区を変えてみた。世田谷は40台がピークで働き盛りかつ、子育ても活発であろうことがうかがえる。子供は相対的にはやや少ないが、国内では多い方に思える。ここはそのデータも入れるべきところではある。
また20歳で値が大きく飛んでいる。おそらく大学、社会人として上京による流入が多いことを示すだろう。このあたりは都内特別区での違いも気になるところではある。
反対に気仙沼は70歳代の団塊がピークだ。やはり地方の高齢化が顕在化している。またアラサーで凹んでおり結婚を期にした流出が深刻そうだ。これは意外にも男女差はあまり見られない。このあたりのジェンダー観は案外フラットでリベラルなのかもしれない。凹みの反動でティーンがややピークにも見える。将来的な政策課題として、ここの世代をなるべく流出させない努力も非常に重要だろう。
こうした経時変化においては、各年代ごとのデータを収集したコーホート分析が有効だ。さすがに同一市区においてデータ形式が変わっているとは思えないので、これは追加分析のしがいもありそうだ。
散布図

世代ごとに散布図にしてみた。分かりやすくその階級最小値:数式で~前をとったでラベル表示と大きさ変更をしている。さらにこれを自動のクラスタリングにかけた。クラスター数も自動で適切な数に調整される。もちろんマニュアルで操作もできる。このあたりはPythonのK-meansとも遜色ないレベルだ。
図上にコメントしたようにこのクラスタリングはまさにライフステージにキレイに分かれている。これほどクリティカルで有効そうなクラスターもそうない。これは日本人全体で共有している実感ともそう変わらないだろう。
要は地方は高齢化が深刻で都会に比べその数が多く、反対に現役世代は都会に集中してしまっている。
しかし今回の分析で興味深いのは被扶養者、黄色のクラスターだ。子供や前期高齢者の地域差はあまり大きくない。ここに日本の活路がありそうだ。定年後のセカンドキャリアや育児支援だ。
とはいえ今回は2都市でしか比較しておらず、世田谷も特別区では高齢者や富裕層が多いイメージがありやや例外的な印象も否めない。そうした面は今後の課題とも言える。
だが以上、データ成形の苦労に対応するインサイトは得られたと考える。読者も動的変化を見つつ、洞察を深めてもらいたい。
感想
やはりデータ成形が大変だった。こういうルール作りが何かと誰もやりたがらないが大切だ。とはいえ、ただの印象の話が一部データに裏打ちできたのは嬉しい。
地方都市としての仙台や都内でも例えば新宿区との比較ともしてみたかったものの、リソース的に余力がなくできなかったのは残念だった。
また今回は2都市の比較の中でも人口のみになってしまった。漁業が得意で天然資源の豊かな地域の代表として、1次産業を筆頭とした経済活動の差分も出したかった。これらも下記のリンクで同様にあるので、折を見て取り組みたいところだ。
最後にVizとしては比較的標準的なものに落ち着いたが、三角関数等を駆使して、既存の枠組みに捕らわれない表現にも挑戦したいと所信表明したところで、今回は筆を置くこととする。
参考文献
データは各市区の役場22/7/13現在の最新の統計データを利用しています。