大量データをどうにか図示したい場面があった。
基本的な統計の説明としては、平均値、中央値で基本的に事足りるが、やはり全体感を把握しておきたいというふんわりしたニーズはありがちだ。
他人が思っていなくても自分で抑えておきたいという気持ちもある。
そんな場面。
前述の平均値や中央値は、後者はコツがあるものの、SQLで簡単に一発で出せる。
問題は分布の様子だ。
ひとまずデータは用意しなければならない。
クラウドにある場合、ファイル分割を駆使したりしながらローカルに持ってくる。
クラウドにPythonがアクセスできれば、話は早くていくらか楽なのだが、その整備方法の知見が私には足りない。
ちなみにクラウドのエクスポートも面倒くさそうだったが、案外正規表現を用いて簡単にできることに最近気づいた。日々勉強である。
そんなこんなで分割されたファイルをDataFrameとして仮想的に一時的に結合しつつ、その描画をさせてみた。
分布の描画としてはヒストグラムが一般的ではあるものの、統計量の把握には弱いので文脈的に箱ひげ図を採用してみた。
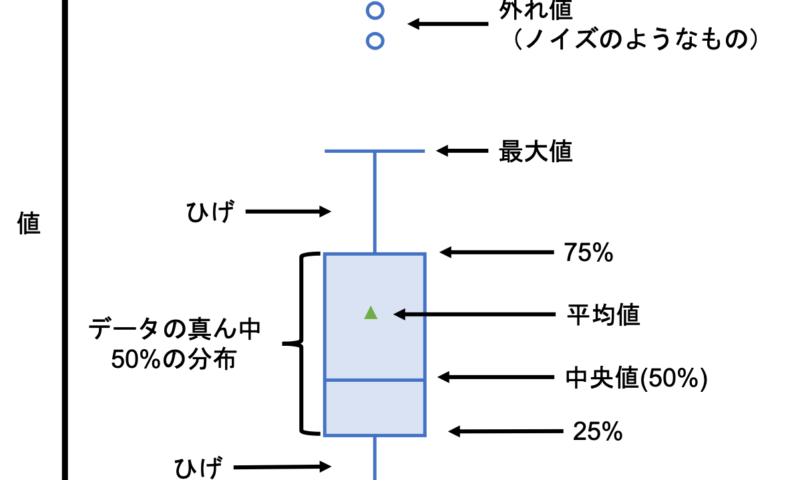
またscenariがいくつかあったので、網羅的に一般化させた。
とはいえ具体を示したのは当然ながらGPT。
import os import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt # フォルダの全探索 def explore_folders(root_folder): csv_files = [] for root, dirs, files in os.walk(root_folder): for file in files: if file.endswith(".csv"): csv_files.append(os.path.join(root, file)) return csv_files # CSVの結合とデータフレームの作成 def combine_csv_files(csv_files): dfs = [] for file in csv_files: df = pd.read_csv(file) dfs.append(df) combined_df = pd.concat(dfs) return combined_df # フォルダのパスと結果のデータフレームの辞書を作成 def create_folder_df_dict(csv_files): folder_df_dict = {} for file in csv_files: folder = os.path.dirname(file) if folder not in folder_df_dict: folder_df_dict[folder] = pd.read_csv(file) else: df = pd.read_csv(file) folder_df_dict[folder] = pd.concat([folder_df_dict[folder], df]) return folder_df_dict def visualize_data(data, column, folder_title): # 結合 data['x'] = data['xxx'] + '_' + data['yyy'] # グラフのタイトルを設定 graph_title = f"{folder_title} - {column}" # 絞り込む組み合わせのデータ combinations = [ ('AAA', 'BBB'), ('AAA', 'CCC'), ] # 組み合わせに絞り込んだデータのみ抽出 filtered_data = data[data.apply(lambda row: (row['xxx'], row['yyy']) in combinations, axis=1)] # 箱ひげ図の作成 ax = sns.boxplot(x=column, y='x', data=filtered_data, showmeans=True) plt.xlabel(column) plt.ylabel('x') plt.title(graph_title) plt.xticks(fontsize=8) # y軸の範囲を平均値の10倍に設定 mean = filtered_data[column].mean() xlim = mean * 10 ax.set_xlim(0, xlim) plt.savefig(root_folder + f"/result/{graph_title}.png", dpi=300, bbox_inches='tight') plt.close() # フォルダのパス # フォルダのパス root_folder = r"C:\Users\root" # ファイルの配下のフォルダを全探索 csv_files = explore_folders(root_folder) # フォルダごとにCSVを結合したデータフレームを作成 combined_df = combine_csv_files(csv_files) # フォルダごとのデータフレームの辞書を作成 folder_df_dict = create_folder_df_dict(csv_files) # データの可視化と出力 for folder, df in folder_df_dict.items(): # フォルダ名からタイトルを作成 folder_title = os.path.basename(os.path.dirname(folder)) # scenario1の箱ひげ図 visualize_data(df, 'scenario1', folder_title) # scenarioの箱ひげ図 visualize_data(df, 'scenario2', folder_title)
こちらはもう少しいわばおふざけ。
飲み会の幹事におけるコンテンツとして、画像編集を試みている。
一般化されたWebアプリケーションサービスでも目的自体は達せられるが、飲ませる画像のプライバシーや権利問題から、ローカルでできた方が安牌なので、勉強がてら模索してみた。
以下のコードは画像をクロマキー合成的に抜いて影絵的な出力ができる。
こちらもフォルダ内を探索する一般化を入れている。
画像ごとにファイル名を指定して実行させるのも面倒なんでね。
同様に顔年齢を加工するものや合成もやってみたいところではあるものの、これはモジュール系の準備が複雑で難しい。
それに付随するが顔そのものやパーツの特定に学習データを用いるのもレベル感が異なっている。
Pythonを数年使いつつもML、DLはそもそもほぼ触れてこなかったが、俄然壁にぶち当たっている印象だ。
[機械学習]TargetCLIPで顔を合成してみる - TeDokology
下記のコードもプロセス的には理解できるものの、ここの関数はふーんという感じで、以上でも以下でもない。
あと画像を複数枚扱わせている割に軽くてビックリ。
まあZoomの背景設定もロジックは同じだろうし、重ければ成り立たないか。
import os from PIL import Image, ImageOps # 入力フォルダと出力フォルダのパスを指定する input_folder = r"C:\Users\face_img\source_face_img" output_folder = r"C:\Users\face_img\output_face_img" # 背景色を指定する(R, G, Bの値) background_color = (255, 255, 255) # 白色の背景 # 画像フォルダ内のファイルを走査する for file in os.scandir(input_folder): if file.is_file(): # ファイルの絶対パスを取得する input_path = file.path # 画像を読み込む image = Image.open(input_path) # 画像をRGBA形式に変換する image_rgba = image.convert("RGBA") # 画像のピクセルデータを取得する pixels = image_rgba.load() # 画像の幅と高さを取得する width, height = image_rgba.size # 背景色との差の閾値を指定する threshold = 30 # 画像を走査して背景色との差を計算し、透明度を設定する for y in range(height): for x in range(width): r, g, b, a = pixels[x, y] if abs(r - background_color[0]) <= threshold and \ abs(g - background_color[1]) <= threshold and \ abs(b - background_color[2]) <= threshold: # 背景色に近いピクセルは透明にする:逆 pixels[x, y] = (r, g, b, 0) else: # それ以外のピクセルは不透明にする:逆 pixels[x, y] = (r, g, b, 255) # 縁取りを追加する outline_color = (0, 0, 0, 255) # 縁取りの色(黒色) outline_width = 2 # 縁取りの幅 # 縁取りを追加するために、画像を縮小する scaled_image = image_rgba.resize((width - 2 * outline_width, height - 2 * outline_width)) # 縮小された画像の背景色を透明にする pixels = scaled_image.load() for y in range(height - 2 * outline_width): for x in range(width - 2 * outline_width): r, g, b, a = pixels[x, y] if abs(r - background_color[0]) <= threshold and \ abs(g - background_color[1]) <= threshold and \ abs(b - background_color[2]) <= threshold: # 背景色に近いピクセルは透明にする pixels[x, y] = (r, g, b, 0) # 縮小された画像を元のサイズに戻す outlined_image = Image.new("RGBA", (width, height), outline_color) outlined_image.paste(scaled_image, (outline_width, outline_width)) # JPEG形式で保存する output_filename = os.path.splitext(file.name)[0] + ".jpg" output_path = os.path.join(output_folder, output_filename) outlined_image.convert("RGB").save(output_path, "JPEG")
スーツ姿の私の出力例

黒点ならぬ白点は謎。
局所的に明るいということだろうから、顔が反射でテカっていたとかそんなところか。
後記的に、
効率はGPTで劇的に上がってるものの、Pythonでも触れていなかった画像系だとことさら面倒というか会話のリレーが増えてしまった。
コードというよりファイルの特性の問題の要素も大きいが、PNGで出力して透明な部分が使いにくそうだったので、JPEGにさせたら、ミスコミュニケーションで全然違う形式になってしまったり。
文脈があるので段々司令が雑になりがちだが、そのあたりは予防的に丁寧にやった方が、急がば回れで却って楽なのかもしれない。
今回はGPT3.5で済ませたが、4にアップデートしたりCopilotにすればまた変わりそうなので、今度の3連休とかに試してみたい。
一生そう思っているものの、イマイチタイミングを掴みそこねているw